[Hadoop]chukwa与ganglia的区别
本文共 1135 字,大约阅读时间需要 3 分钟。
众所周知, hadoop 是运行在分布式的集群环境下,同是是许多用户或者组共享的集群,因此任意时刻都会有很多用户来访问 NN 或者 JT ,对分布式文件系统或者 mapreduce 进行操作,使用集群下的机器来完成他们的存储和计算工作。当使用 hadoop 的用户越来越多时,就会使得集群运维人员很难客观去分析集群当前状况和趋势。比如 NN 的内存会不会在某天不知晓的情况下发生内存溢出,因此就需要用数据来得出 hadoop 当前的运行状况。
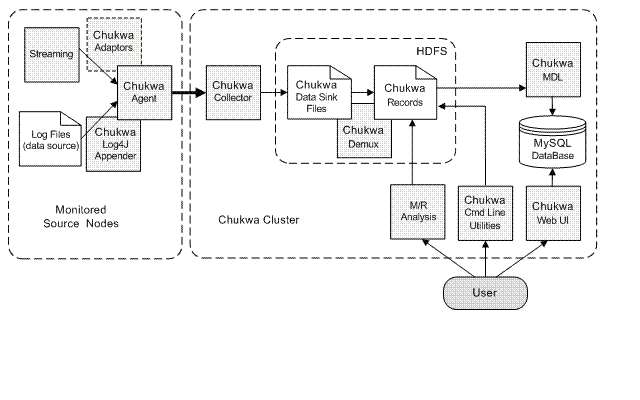
Chukwa 就是利用了集群中的几个进程输出的日志,如 NN,DN,JT,TT 等进程都会有 log 信息,因为这些进程的程序里面都调用 log4j 提供的接口来记录日志,而到底日志的物理存储是由 log4j.properties 的配置文件来配置的,可以写在本地文件,也可以写到数据库。 Chukwa 就是来控制这些日志的记录,由 chukwa 程序来接替这部分工作,完成日志记录和采集工作。 Chukwa 由以下几个组件组成: agent 收集各个进程的日志,并将收集的日志发送给 collector 。 Collector 收集 agent 发送为的数据,同时将这些数据保存到 hdfs 上, MR job 利用 mapreduce 来分析这些数据。 DumpTool 将结果下载保存到 mysql 数据库。 HICC 将数据展现出来。更多信息: http://incubator.apache.org/chukwa/
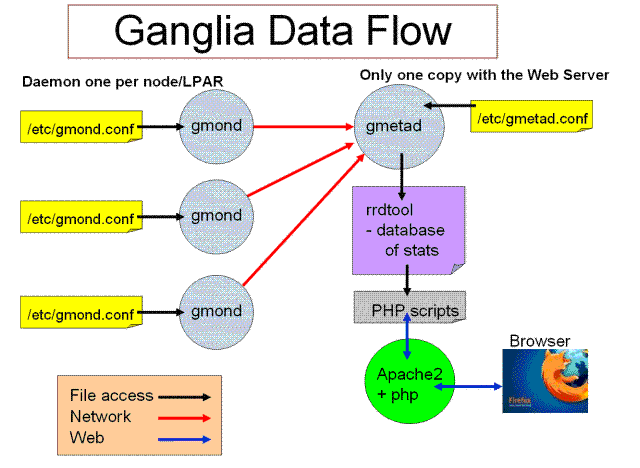
Ganglia 则更偏向于操作系统低层一点的监控,主要是收集集群中的各个机器的 CPU 使用情况,内存使用情况,磁盘 I0, 网络 IO ,磁盘容量等,更像是 windows 的任务管理器,只不过它是管理分布集群机器。类似的,它也由以下组件组成:数据采集组件,每隔一段时间采集一次数据,然后将数据发送给收集器,收集器收集好数据,再将数据保存到数据库,最后一个叫做 rrdtool 通过图形化来展现数据。更值的一提的是, ganglia 更加通用性,除了收集固定的机器性性外,它还提供了相关插件,可以插入到其他进程,如 JAVA 程序,然后可以收集起这些进程的相关信息。
更多信息: http://ganglia.info/
http://www.javabloger.com/article/j2ee-linux-ganglia-rrdtool-java-mysql-1.html
对于深入了解当前平台的状态以及集群中机器的运行情况, chukwa 和 ganglia 无疑是不错的工具,可以用来去得到相关的准确数据,用来知道当前的运行状态,为未来做决策,推断出当前的瓶颈,以及优化相关的应用程序等。
Chukwa 就是利用了集群中的几个进程输出的日志,如 NN,DN,JT,TT 等进程都会有 log 信息,因为这些进程的程序里面都调用 log4j 提供的接口来记录日志,而到底日志的物理存储是由 log4j.properties 的配置文件来配置的,可以写在本地文件,也可以写到数据库。 Chukwa 就是来控制这些日志的记录,由 chukwa 程序来接替这部分工作,完成日志记录和采集工作。 Chukwa 由以下几个组件组成: agent 收集各个进程的日志,并将收集的日志发送给 collector 。 Collector 收集 agent 发送为的数据,同时将这些数据保存到 hdfs 上, MR job 利用 mapreduce 来分析这些数据。 DumpTool 将结果下载保存到 mysql 数据库。 HICC 将数据展现出来。更多信息: http://incubator.apache.org/chukwa/
Ganglia 则更偏向于操作系统低层一点的监控,主要是收集集群中的各个机器的 CPU 使用情况,内存使用情况,磁盘 I0, 网络 IO ,磁盘容量等,更像是 windows 的任务管理器,只不过它是管理分布集群机器。类似的,它也由以下组件组成:数据采集组件,每隔一段时间采集一次数据,然后将数据发送给收集器,收集器收集好数据,再将数据保存到数据库,最后一个叫做 rrdtool 通过图形化来展现数据。更值的一提的是, ganglia 更加通用性,除了收集固定的机器性性外,它还提供了相关插件,可以插入到其他进程,如 JAVA 程序,然后可以收集起这些进程的相关信息。
更多信息: http://ganglia.info/
http://www.javabloger.com/article/j2ee-linux-ganglia-rrdtool-java-mysql-1.html
对于深入了解当前平台的状态以及集群中机器的运行情况, chukwa 和 ganglia 无疑是不错的工具,可以用来去得到相关的准确数据,用来知道当前的运行状态,为未来做决策,推断出当前的瓶颈,以及优化相关的应用程序等。
转载地址:http://kcqta.baihongyu.com/
你可能感兴趣的文章
mysql性能的检查和调优方法
查看>>
项目管理中的导向性
查看>>
Android WebView 学习
查看>>
(转)从给定的文本中,查找其中最长的重复子字符串的问题
查看>>
HDU 2159
查看>>
spring batch中用到的表
查看>>
资源文件夹res/raw和assets的使用
查看>>
UINode扩展
查看>>
LINUX常用命令
查看>>
百度云盘demo
查看>>
概率论与数理统计习题
查看>>
初学structs2,简单配置
查看>>
Laravel5.0学习--01 入门
查看>>
时间戳解读
查看>>
sbin/hadoop-daemon.sh: line 165: /tmp/hadoop-hxsyl-journalnode.pid: Permission denied
查看>>
@RequestMapping 用法详解之地址映射
查看>>
254页PPT!这是一份写给NLP研究者的编程指南
查看>>
《Data Warehouse in Action》
查看>>
String 源码浅析(一)
查看>>
Spring Boot 最佳实践(三)模板引擎FreeMarker集成
查看>>